What Is TinyML? How AI Runs on Chips Smaller Than Your Thumbnail (2026)
Updated June 2026 · 11-minute read

There is a category of AI that rarely makes headlines but runs in hundreds of millions of devices around the world. It does not need a data centre. It does not need a neural engine the size of a cigarette lighter. It runs on microcontrollers with as little as 256 kilobytes of RAM, drawing less power than a small LED, often on a coin battery that lasts for months or years. This category is called TinyML.
TinyML sits at the intersection of machine learning and embedded systems. It is the technology that lets your smart thermostat recognise your voice without connecting to the cloud, lets your fitness tracker detect that you are doing push-ups rather than lying still, and lets your smart doorbell identify a person versus a passing car without uploading every frame of video. Understanding TinyML helps explain why modern AI gadgets can be so small, so cheap, so power-efficient, and so private.
The Scale Problem That TinyML Solves
To understand why TinyML exists as a distinct field, you need to understand the enormous gap between the hardware AI usually runs on and the hardware that powers most of the world's connected devices.
Large AI models run on hardware with hundreds of gigabytes of RAM, thousands of processing cores, and power consumption measured in hundreds of watts. A high-end server GPU used for AI training consumes as much power as a small household appliance running continuously. Even consumer AI hardware like the Neural Engine in an iPhone or the Tensor chip in a Pixel phone requires a battery measured in thousands of milliamp-hours and generates enough heat that phones need thermal management systems.
But most connected devices in the world are not phones or laptops. They are microcontrollers: small, cheap chips that control the logic in smoke detectors, glucose monitors, industrial sensors, agricultural monitoring nodes, hearing aids, wearable patches, and thousands of other devices. A typical microcontroller might have 256KB to 1MB of RAM, run at 48 to 400 MHz, and draw a few milliwatts of power. A coin battery can run one for months.
Until TinyML, putting AI on these devices was not practical. The smallest useful neural networks were too large for kilobytes of memory and too computationally demanding for low-MHz processors. TinyML is the set of techniques, frameworks, and optimised models that make AI inference work within these extreme constraints.
How TinyML Gets AI Models Small Enough
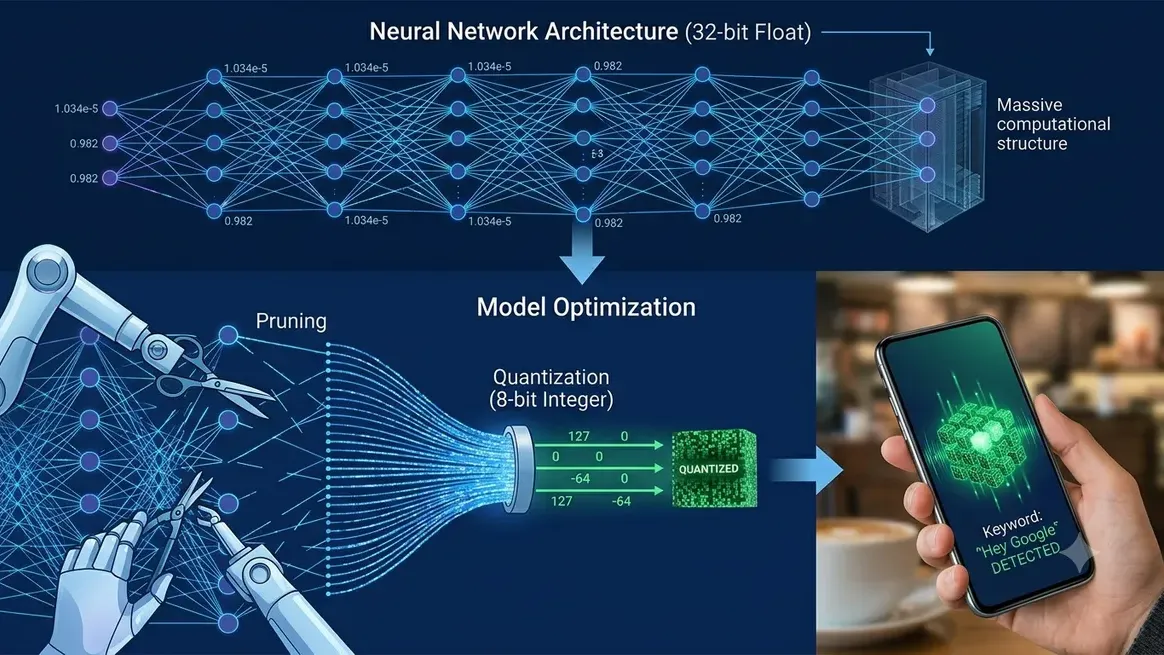
A neural network trained in a research environment might have millions or billions of parameters, each stored as a 32-bit floating point number. Even a relatively small model with one million parameters requires 4 megabytes just to store the weights, which is already larger than the entire RAM of many microcontrollers. Running inference on such a model requires matrix multiplications with these large floating point numbers, which demands a fast processor and significant temporary memory.
TinyML uses several techniques to shrink these requirements by orders of magnitude.
Quantisation
Quantisation reduces the numerical precision of model weights and activations. Instead of representing each number as a 32-bit float (which can express values with enormous precision across a huge range), quantisation converts them to 8-bit integers or even 4-bit integers. This reduces memory requirements by 4 to 8 times immediately.
The accuracy cost of quantisation is usually small. A model quantised from 32-bit float to 8-bit integer typically loses less than 1 percent accuracy on most tasks. The efficiency gain is enormous: 8-bit integer arithmetic is faster and uses less energy than 32-bit floating point arithmetic on the simple processors inside microcontrollers, which often have dedicated integer accelerators but no floating point hardware at all.
Pruning
Neural network training often produces models where many of the learned weights are very close to zero and contribute minimally to the output. Pruning identifies and removes these near-zero weights, creating a sparser model with fewer parameters. A well-pruned model can be 50 to 90 percent smaller than the original while maintaining most of its accuracy, because the remaining weights carry the important learned information.
Knowledge distillation
Knowledge distillation trains a small model to imitate the behaviour of a large, accurate model. The large model is called the teacher. The small model is called the student. The student is trained not just on the original training data but also on the outputs of the teacher, learning to replicate the teacher's reasoning patterns in a compressed form. The result is a small model that performs significantly better than a small model trained from scratch, because it has been guided by the knowledge encoded in the large model.
Architecture design
Some neural network architectures are designed from the ground up for efficiency rather than maximum accuracy. MobileNet, designed by Google, uses depthwise separable convolutions that compute the same spatial filtering as standard convolutions but with a fraction of the multiply-accumulate operations. EfficientNet and SqueezeNet are similar architectures optimised for constrained environments. These architectures form the basis of many TinyML models deployed in consumer devices.
Size comparison in practice: A full-size BERT language model has 110 million parameters and requires around 440MB of storage. A TinyBERT model distilled for embedded use has around 14 million parameters and requires around 55MB. A further quantised and pruned version can fit in under 5MB while still handling basic natural language classification tasks. A simple wake word detection model for "Hey Alexa" can run in under 100KB.
TinyML Frameworks and Tools
Several software frameworks have emerged specifically for deploying machine learning on microcontrollers and embedded systems.
TensorFlow Lite Micro
TensorFlow Lite Micro, developed by Google, is the most widely used TinyML runtime. It is a version of TensorFlow Lite further stripped down to run without dynamic memory allocation, without an operating system, and with a binary size starting around 16KB. It supports a subset of TensorFlow operations that have been hand-optimised for common microcontroller architectures including ARM Cortex-M series, Xtensa, and RISC-V.
Google's reference hardware for TinyML development is the Arduino Nano 33 BLE Sense, which includes an ARM Cortex-M4 processor, 1MB of flash, 256KB of RAM, and a collection of sensors including accelerometer, gyroscope, microphone, and temperature sensors. This roughly $35 development board can run keyword spotting, gesture recognition, and simple image classification models in real time.
Edge Impulse
Edge Impulse is a development platform that makes TinyML accessible to engineers without deep machine learning expertise. You collect sensor data through the platform, label it, train a model using a web interface, and deploy the optimised result to your target hardware. Edge Impulse handles the quantisation, optimisation, and code generation automatically. It supports over 80 target boards and has become the most popular tool for deploying TinyML in product development.
ONNX Runtime for Mobile and Embedded
ONNX Runtime provides inference capability for models in the ONNX format, which is a common interchange format that models trained in PyTorch, TensorFlow, and other frameworks can be exported to. Microsoft developed ONNX Runtime, and its mobile and embedded variants support deployment on ARM processors with power and memory constraints relevant to IoT and wearable applications.
TinyML in Consumer Gadgets You Already Own
TinyML is not a future technology. It is running in devices on your wrist, in your kitchen, and in your ears right now.
Wake word detection in smart speakers
When an Amazon Echo or Google Nest speaker listens for "Hey Alexa" or "Hey Google," it runs a TinyML keyword spotting model continuously on a dedicated low-power microcontroller. The main processor, which handles the actual Alexa or Assistant response, stays in a low-power sleep state. Only when the TinyML model detects a high-confidence match for the wake word does it wake the main processor and start sending audio to the cloud.
This architecture means the always-on listening consumes a few milliwatts of power rather than the watts that continuous cloud audio streaming would require. The wake word model itself might be under 500KB and runs inference in under 10 milliseconds, hundreds of times per second, continuously.
Activity recognition in fitness trackers
The Fitbit, Garmin, and Apple Watch features that distinguish between walking, running, cycling, swimming, and stair climbing all rely on machine learning models running on embedded processors that interpret raw accelerometer and gyroscope data. These models run continuously on the wearable's low-power processor rather than on the main application processor, preserving battery life.
The models classify 3-axis accelerometer data sampled at 25 to 100Hz into activity categories using convolutional or recurrent neural network architectures that have been quantised and pruned to fit in hundreds of kilobytes. They run inference every few seconds to update the current activity classification, consuming microwatts between inference cycles.
Fall detection
Apple Watch's fall detection, which has saved documented lives by automatically calling emergency services when a user falls and does not respond, runs a TinyML model that analyses accelerometer and gyroscope data for patterns characteristic of a fall followed by impact. The model must run continuously, detect the event within seconds of it occurring, distinguish a genuine fall from vigorous exercise or dropping the phone, and do this on a watch that needs to last a full day on a small battery.
Always-on voice in true wireless earbuds
Sony WH-1000XM6 and similar earbuds use embedded AI for two always-on functions: noise cancellation and Adaptive Sound Control. The noise cancellation DSP runs a model that continuously analyses incoming audio and generates an inverted signal to cancel it, operating with latency under 2 milliseconds. The Adaptive Sound Control feature runs a simpler classifier that uses motion sensor data and ambient audio characteristics to identify activities like walking, running, or sitting still, and adjusts the noise cancellation behaviour accordingly.
Smart ring health monitoring
The Oura Ring 4 and Samsung Galaxy Ring both run embedded firmware that continuously reads optical heart rate sensors and temperature sensors, applies signal processing and machine learning to extract biometric metrics from the raw sensor data, and stores compressed results in internal memory. The ring form factor constrains battery to a tiny cell, making power efficiency critical. The health monitoring firmware uses TinyML techniques to extract maximum information from sensor data while consuming minimum power.
The Hardware: Microcontrollers Built for TinyML
The embedded processor market has responded to TinyML demand with a generation of microcontrollers that include dedicated hardware for neural network inference.
Chip | Maker | AI Feature | RAM | Typical Use |
|---|---|---|---|---|
STM32 with NeuralART | ST Microelectronics | Dedicated neural accelerator | Up to 1MB | Industrial, wearable |
Ambiq Apollo5 | Ambiq | AI co-processor | Up to 4MB | Smart wearables |
nRF9161 | Nordic Semiconductor | AI inference on Cortex-M33 | 256KB | IoT sensors, trackers |
MAX78002 | Analog Devices | Ultra-low-power CNN accelerator | 384KB | Always-on inference |
Syntiant NDP120 | Syntiant | Neuromorphic audio AI | On-chip SRAM | Wake word, audio events |
RP2350 | Raspberry Pi | RISC-V with ML acceleration | 520KB | Hobbyist, education, prototyping |
The Syntiant NDP chip family deserves particular attention. Syntiant builds chips specifically for always-on audio AI that consume under 140 microwatts during inference. This is so efficient that a standard hearing aid battery can power a Syntiant chip for the full expected battery life of the device while running keyword detection and audio event classification continuously. Several commercial products including laptop wake word detection and smart home sensors use Syntiant chips specifically for their ultra-low-power always-on AI capability.
TinyML vs NPU: Understanding the Spectrum
TinyML and NPUs (Neural Processing Units in phones and laptops) both do on-device AI, but at very different scales. Understanding where they sit on the spectrum clarifies the terminology.
Category | Example Hardware | Memory | Power | Model Size |
|---|---|---|---|---|
TinyML (microcontroller) | ARM Cortex-M4, Syntiant | 256KB to 4MB | Microwatts to milliwatts | Under 1MB |
Edge AI (mobile NPU) | Apple Neural Engine, Qualcomm AI Engine | Gigabytes | Hundreds of milliwatts | Tens to hundreds of MB |
Cloud AI | Data centre GPU clusters | Hundreds of GB | Hundreds of watts | Tens to hundreds of GB |
TinyML handles the lowest-power, always-on tasks: wake word detection, activity classification, anomaly detection, basic gesture recognition. Mobile NPUs handle richer tasks: large language model inference, image generation, real-time translation, speech recognition. Cloud AI handles the largest tasks: training models, frontier reasoning, generating long documents.
Many products use all three levels in combination. A smart speaker uses TinyML for wake word detection, then wakes its application processor (which may have a small NPU) to do local preprocessing, then sends the query to cloud AI for the actual response. This tiered approach gets the best of all three levels: always-on at near-zero power, fast local processing for latency-sensitive steps, and cloud capability for complex tasks.
Why TinyML Matters for Privacy
TinyML has a privacy implication that is often overlooked in discussions about AI and privacy. When AI inference runs on a microcontroller inside a sensor, the raw sensor data never needs to leave the device. Only the inference result, which is a much smaller and less sensitive piece of information, needs to be transmitted.
Consider a smart security camera with on-device TinyML person detection. Instead of streaming all video to the cloud for analysis, the camera's microcontroller processes each frame locally. If no person is detected, nothing is transmitted. If a person is detected, only an alert is sent, not the raw video. The video stays on the device unless the user explicitly requests it. This is a fundamentally more privacy-preserving architecture than cloud-analysed video.
The same principle applies to health sensors. A glucose monitor with TinyML can process the raw optical sensor data on the device and report only the estimated glucose value, not the raw continuous light absorption data that the inference is based on. A hearing aid with TinyML can process audio entirely on the device and never transmit the raw audio of the wearer's conversations anywhere.
The Future of TinyML
TinyML is moving rapidly in several directions that will make AI more pervasive at the lowest levels of the hardware stack.
Continual learning on-device, where a deployed model can update itself based on new data without retraining in the cloud, is an active research area. The challenge is doing this in the memory and compute constraints of a microcontroller while avoiding catastrophic forgetting of previously learned behaviour. Several research groups have demonstrated continual learning on Cortex-M4 class hardware.
Neuromorphic computing, which processes information using spike-based computation inspired by biological neurons rather than conventional matrix multiplication, offers the potential for even lower power consumption than current TinyML approaches. Intel's Loihi 2 chip and several research neuromorphic processors have demonstrated orders-of-magnitude lower power consumption than conventional approaches for certain sensor processing tasks. This remains primarily a research area but has implications for next-generation ultra-low-power AI sensors.
Transformer models in TinyML is another active frontier. The transformer architecture that powers modern language models requires significant memory for its attention mechanisms, which has traditionally made it unsuitable for microcontrollers. Research into quantised, pruned, and distilled transformers has demonstrated that small but useful transformer models can now run on devices with as little as 1MB of RAM, opening natural language processing capability at the very edge of the network.
Frequently Asked Questions
What is the difference between TinyML and Edge AI?
TinyML refers specifically to machine learning on microcontrollers and very resource-constrained embedded processors, typically with memory measured in kilobytes and power consumption in microwatts to milliwatts. Edge AI is a broader term that includes TinyML but also covers AI on more capable edge devices like smartphones, tablets, and small embedded computers with gigabytes of RAM. All TinyML is Edge AI, but not all Edge AI is TinyML. The distinction matters because the techniques required to run AI on a microcontroller with 256KB of RAM are substantially different from those used on a phone with an NPU.
Can TinyML run large language models?
Not in any meaningful sense. Large language models with billions of parameters require gigabytes of memory and fast processors far beyond what microcontrollers provide. What TinyML can run are small language models for specific tasks: keyword spotting, simple intent classification, sentiment detection on short text. The Phi-1 family of small language models from Microsoft can run on devices with around 1GB of RAM, which is still far above microcontroller capacity but represents the frontier of very small language models that might eventually be adapted for more capable embedded processors.
Which programming languages are used for TinyML?
C and C++ remain the primary languages for TinyML deployment on microcontrollers because they give direct control over memory and produce efficient compiled code. TensorFlow Lite Micro and Edge Impulse both generate C++ inference code. The training of models is typically done in Python using PyTorch or TensorFlow, and then the trained model is converted, quantised, and compiled into C++ code for deployment. MicroPython is available on some higher-end embedded boards and provides a Python interface to lower-level ML operations, though with performance overhead compared to native C++.
How do I get started with TinyML?
The most accessible starting point is the Arduino Nano 33 BLE Sense or the Raspberry Pi RP2040 or RP2350 paired with Edge Impulse. Edge Impulse provides a free web-based platform where you can collect sensor data from the board, train models without writing ML code, and deploy them with generated Arduino-compatible C++ code. The book "TinyML" by Pete Warden and Daniel Situnayake (available through O'Reilly) is the most comprehensive introduction to the field for people with some embedded development background.
What sensors work best for TinyML applications?
Accelerometers and microphones are the most common TinyML sensor inputs because they produce relatively low-bandwidth data streams that well-established model architectures can process efficiently. A 3-axis accelerometer sampled at 100Hz produces 300 values per second, which is manageable even on a slow processor. Image sensors can work with TinyML using aggressive downsampling (96x96 pixel grayscale is common for microcontroller image classification) but require more memory and compute than 1D sensor inputs. Temperature, pressure, and gas sensors produce very low-bandwidth data that is easy to process but may require longer time windows to extract meaningful features.
This article covers TinyML concepts and tools as of June 2026. The field advances rapidly, with new model compression techniques, hardware platforms, and frameworks released regularly. Sources include research from Harvard's Edge ML Lab, Google's TensorFlow Lite Micro team, and the TinyML Foundation.